
![]() Front Page
Front Page
RESEARCH TOPICS
![]() Automatic and Semi-automatic Essay Grading
Automatic and Semi-automatic Essay Grading
![]() Evaluation of the Natural Language Parsers
Evaluation of the Natural Language Parsers
![]() Plagiarism Detection in Software Projects
Plagiarism Detection in Software Projects
![]() Visualization of the Social Interaction in Virtual Environments
Visualization of the Social Interaction in Virtual Environments
WHO & WHAT
![]() People & Alumni
People & Alumni
![]() Publications
Publications
LINKS
![]() Educational Technology @ Department of Computer Science
Educational Technology @ Department of Computer Science
![]() Department of Computer Science in University of Joensuu
Department of Computer Science in University of Joensuu
FUNDERS
![]() National Technology Agency of Finland (TEKES)
National Technology Agency of Finland (TEKES)
![]() European Commission - Research Directorate
European Commission - Research Directorate
![]() Discendum
Discendum
![]() Karjalainen
Karjalainen
![]() Lingsoft
Lingsoft
![]() Tikka Communications
Tikka Communications
![]() Intranet (password required)
Intranet (password required)

A natural language parser is computer software that outputs the structural description of a given character string relative to a given grammar. A grammar specifies how each sentence is constructed from parts. The output of a parser is a parse tree that shows the structure of the analyzed language fragment. Parsers are used as a component of natural language processing (NLP) systems for machine translation, document summarization, message classification and information retrieval, for instance.
Evaluation tools are needed to allow the developers and users to assess NLP systems. Natural language parser evaluation has many focuses: developers need means to track the development of the system they are working on, users are interested in comparison between different NLP systems and funders need information as the basis for their decisions on resource allocation. For evaluation a comparison material or "gold standard is needed. It usually consists of a tree bank or a test suite. In addition to comparison material, metrics are needed for evaluation. One of the main problems in comparative parser evaluation is the fact that parsers are based on different linguistic formalisms and generate analyses which are not directly comparable. Dependency and phrase (or constituency) structures are the two main ways to represent parse trees. Figure 1 shows an example of dependency and constituency trees.
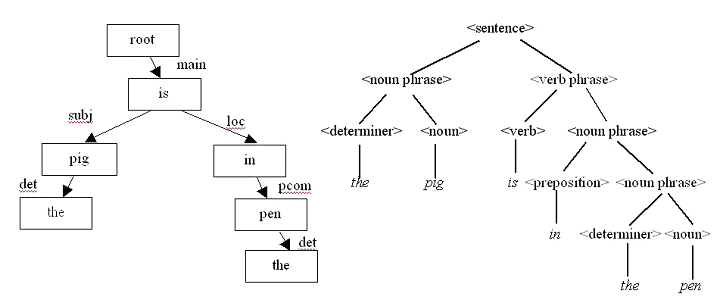
Figure 1: Dependency and phrase structure trees for the sentence "The pig is in the pen".
Despite its known disadvantages, the most widely used evaluation method in natural language parser evaluation is based on a scheme known as PARSEVAL. The scheme uses phrase structure bracketings to compare the output of a parser and an annotated corpus or a treebank. A wide variety of models has been developed since PARSEVAL. None of them has received wide acceptance and PARSEVAL is still being used despite its deficiencies.
The main focus in my research is on intrinsic evaluation of natural language parsers and especially on error analysis. Error analysis provides parser developers with information for guiding their work. A test suite is needed for controlled testing of parser capability in specific linguistic phenomena.
The goals of the research are:
- Study the present annotation and evaluation methods and develop a method that supports intrinsic, comparative and extrinsic evaluation and error analysis,
- develop a parser evaluation application,
- perform evaluation of some natural language parsers by using the developed methods and the software; and
- construct a test suite for evaluating Finnish language parsers.
Research Assistant Tuomo Kakkonen, firstname.lastname@cs.joensuu.fi
References:
Kakkonen, T. (2005) Dependency Treebanks: Methods, Annotation Schemes and Tools. Poster represented at the 15th Nordic Conference of Computational Linguistics (NODALIDA 2005), Joensuu, Finland. (Poster)